

In previous exercises, we used the FILTER() function in order to remove the totals from our data model. Using Power Query, clean data is provided to the data model.
Filtering before the data model improves the performance of the model, and make it easier to work with the model.
In this exercise, we will be using the car sales data that has been used in previous exercises.
Getting the Data
Like previous exercises where we have imported data using Power Query, use the From Text/CSV option under the Data menu.
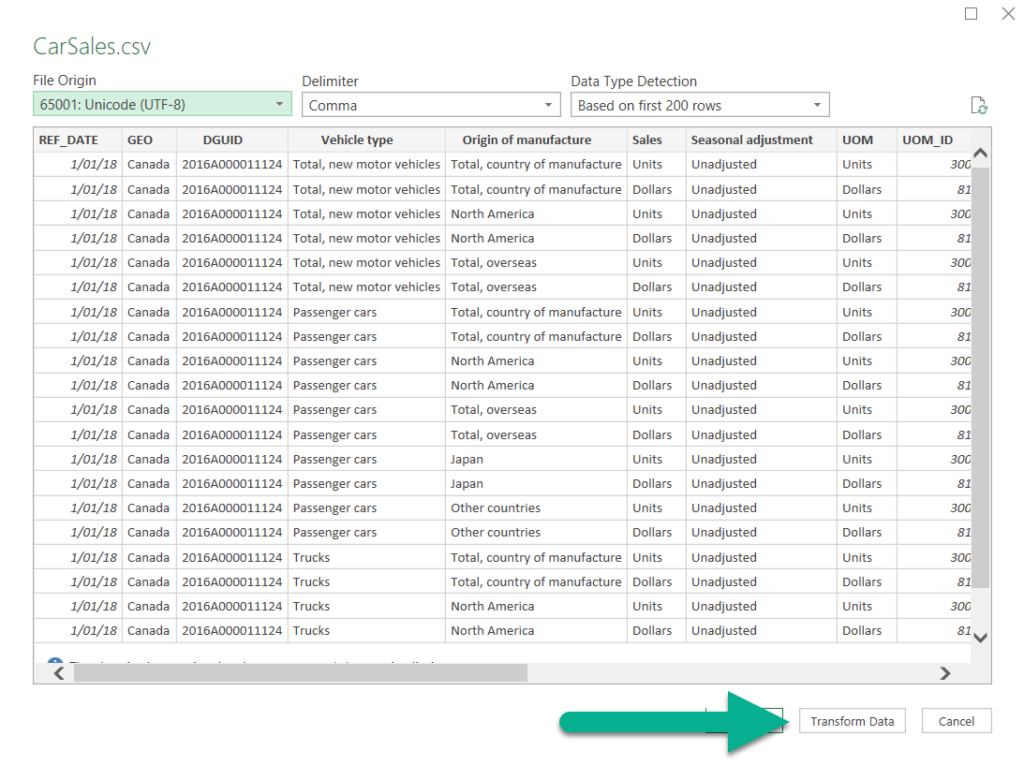
Once the data has been imported, click the Transform Data option in order to bring the table up in Power Query.
Viewing the Data in Power Query
Clicking Transform Data will bring up the Power Query window. This is where all the changes will be made to clean up the data before sending it to the data model.

Within this screen, we will:
- Remove unnecessary columns to reduce the complexity of the model.
- Filter out granular data that is not required for the report.
- Filter out totals that are not required for the report.
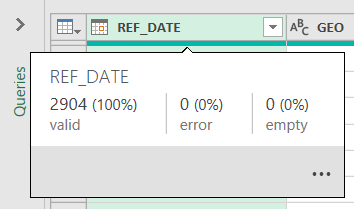
Before we get started, we should note the number of data points in the data source; there are 2,904 rows and 18 columns.
This means that there are 52,272 data points on the report before starting any data cleaning.
Removing unnecessary columns
Many of the columns that are in the data source are not useful for our analysis.
In some cases, such as the SYMBOL and TERMINATED columns, there is a black bar – this reflects that the column is completely empty.
The STATUS column contains a short green bar, meaning most of the data is empty.

Other columns, such as SCALAR_ID and VECTOR are not relevant to the end analysis.

By simply selecting the columns that are not relevant and pressing the Delete button, all irrelevant data can be removed.

This leaves us with only the columns we need for our analysis!
Filter out granular data
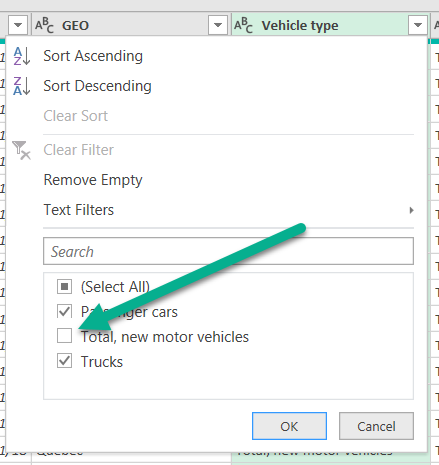
The next step is to remove data where only a total is required. In this case, this is the Origin of Manufacture.
Since the report we are looking to provide is not concerned with where the vehicle is manufactured, we can remove anything other than the total from this column.
Clicking on the filter will bring up a filter option box; this is similar to what is available in Excel.
There is a warning the “List may be incomplete”. This is due to the fact that only the first 1,000 rows are loaded. If the option that you are looking for is not available, click the Load more link above the Cancel button.

In order to select only the “Total, country of manufacture” first unselect all, then select the Total and click OK.

The other item that needs to be filtered is the unit of measurement – this will only require the Units.

Filter out duplicated totals
Since the pivot table will provide the totals, all the rows that contain totals need to be removed to avoid duplication.
This filtering is done the same way as when we filtered for only one item, but instead of filtering to include one item, filter to take one item away.
After completing the Power Query clean of the data, there are only 264 rows and 6 columns.

This is a reduction in the amount of data that we have in the model by nearly 97%, and reduces the size of our Excel file by over 61%.

Impact on existing CALCULATE formulas
The changes that were made in this exercise will not break any of the CALCULATE formulas done in any earlier exercise.
However, the CALCULATE and FILTER is no longer needed to get the total sales to work can be safely removed!


In fact, after removing the FILTER and CALCULATE formulas from the CarSalesTotalValues measure, the UOM and Origin of Manufacture columns can be removed from the data model.
This will reduce file size even more, resulting in an even faster model!

Takeaways
While it can be tempting to use the FILTER() and CALCULATE() functions to get the data that you need for reports, the first step should always be to clean the data as much as possible using Power Query!
This example only touched the surface of what Power Query is capable of. Additional logic and custom formulas can be added to ensure that the data is as clean as possible before being loaded into the data model!